阿里云MaxCompute Spark是MaxCompute提供的兼容开源的Spark计算服务,它在统一的计算资源和数据集权限体系之上,提供Spark计算框架,支持用户以熟悉的开发使用方式提交运行Spark作业,以满足更丰富的数据处理分析场景,aliyunbaike.com网分享:
MaxCompute Spark关键特性
社区原生Spark运行在MaxCompute里面,完全兼容Spark的API,支持多Spark版本同时运行。
提供原生的Spark WebUI供用户查看。
MaxCompute Spark像MaxCompute SQL/MR等任务类型一样,运行在MaxCompute项目开通的统一计算资源中。
完全遵循MaxCompute项目的权限体系,在访问用户权限范围内安全地查询数据。
MaxCompute Spark会和开源保持相同的体验和用户使用习惯,比如开源应用的UI,在线交互等。开源UI对于开源应用的调试至关重要,MaxCompute Spark提供原生的开源实时UI,并且能查询历史日志。某些开源应用提供交互式,也就是把后台引擎拉起后,进行实时交互。
系统结构
MaxCompute Spark是阿里云通过Spark on MaxCompute的解决方案,让原生Spark能够运行在MaxCompute当中。该服务的架构图如下:

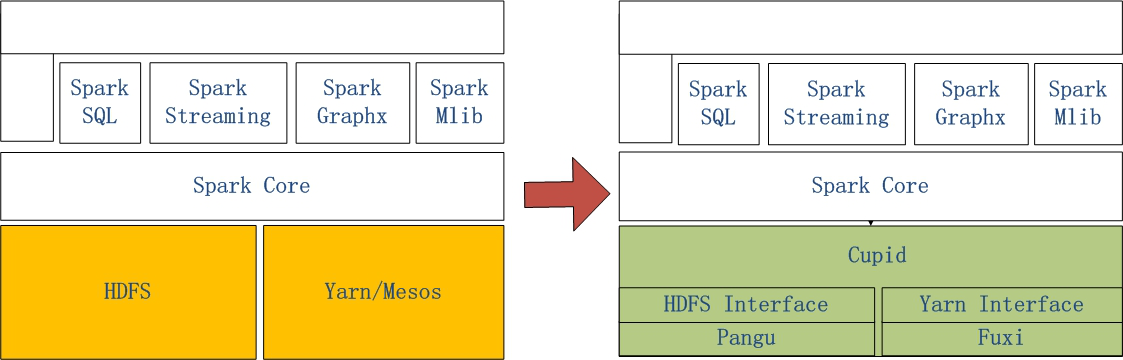 MaxCompute Spark
MaxCompute Spark
左侧是原生Spark的架构图,右边Spark on MaxCompute运行在阿里云自研的Cupid的平台之上,该平台能够原生支持开源社区Yarn支持的计算框架,如Spark等。
2026阿里云服务器租用价格
①阿里云官方活动:https://t.aliyun.com/U/bLynLC 云服务器99元1年,新老同享,多配置特价
②免费7000万Tokens领取:https://t.aliyun.com/U/fPVHqY 开通百炼AI模型平台免费领取超7000万Tokens
③代金券:领券入口 aly.wiki 免费领取12张代金券,总面值2088元优惠券。